
Today, I will also be talking about using neural networks to generate new things, but in this case images rather than text.
The 4th part of the program focuses on GANs (Generative Adversarial Networks), a type of neural network with a peculiar architecture. It is not a single neural network, but two, competing against each other.
In GANs, you have two neural networks: Generator and Discriminator.
The Generator is a CNN (Convolutional Neural Network) that, as the name suggests, given some random input, will generate a new image. This network is trained with the help of the Discriminator.
The Discriminator, on the other hand, is another CNN that given an image will be able to determine if it is real or fake. This network is trained with the labels (in this case, an image set of faces of celebrities) and the output of the Generator.
The Discriminator is trying to improve itself by being able to tell apart generated images from the real ones. The Generator is trying to improve itself by trying to fool the Discriminator.
Two neural networks compete against each other to obtain better results.
Project
To complete this task, we were given two datasets: The MNIST (a set of handwritten numbers) and CelebA (a set of celebrity pictures).
 Sample from MNIST
Sample from MNIST
The idea: first be able to generate new handwritten numbers (which is faster to train) and once your network works correctly, switch to the CelebA set.
 Sample from CelebA
Sample from CelebA
This project presented two challenges:
- You have to build most of the code from scratch
- The code from the previous lessons will not work by default
The main issue was that the output of the Generator should be 28x28x3 (28 pixels width and height, and 3 values for RGB) but the code from the previous lesson gives an output of 32x32x3.
After much trial and error changing the architecture of the network with bad performance results, found a very simple solution: Resize the output!
tf.image.resize_images(logits, (28, 28))
TensorFlow provides image processing functions, that I can use to resize my 32x32 output to 28x28.
At the same time, I was fighting with hyperparameters, until I got something that helped me. I’ve found best results with a very low learning rate (0.0001) if not, the network would start generating weird images pretty quickly.
After a whole day of trial an error, these are the best results I got:
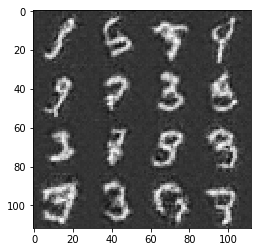 My generated handwritten numbers
My generated handwritten numbers My generated faces
My generated faces
Important to know, that the project specs forced me to do only one single epoch, so I could not use more GPU power/time to improve my solution, instead, I had to optimise my network and parameters until I got something good enough.
Want to learn more Android and Flutter? Check my courses here.